SingleAPI
Unlock the Power of GPT-4 Powered API for Web Data Extraction In today's digital landscape, harnessing the capabilities of advanced technology is essential for effective data management. The GPT-4 powered API for web data extraction offers a seamless solution for businesses looking to gather and analyze information from various online sources. Why Choose GPT-4 Powered API? 1. **Efficiency**: The API streamlines the data extraction process, allowing you to retrieve large volumes of information quickly and accurately. 2. **Versatility**: Whether you need data from websites, social media, or other online platforms, this API adapts to your specific requirements. 3. **User-Friendly**: Designed with ease of use in mind, the API integrates smoothly into your existing systems, minimizing the learning curve. Key Features of the GPT-4 Powered API - **Advanced Natural Language Processing**: Leverage the power of GPT-4 to understand and extract relevant data with precision. - **Customizable Solutions**: Tailor the API to meet your unique data extraction needs, ensuring you get the most relevant information. - **Real-Time Data Access**: Stay updated with the latest information by accessing data in real-time, enhancing your decision-making process. Maximize Your Data Potential By utilizing the GPT-4 powered API for web data extraction, you can enhance your data collection strategies, improve operational efficiency, and gain valuable insights that drive business growth. Don't miss out on the opportunity to elevate your data management practices with this cutting-edge technology.
AI Project Details
SingleAPI review: AI-assisted API for extracting structured web data
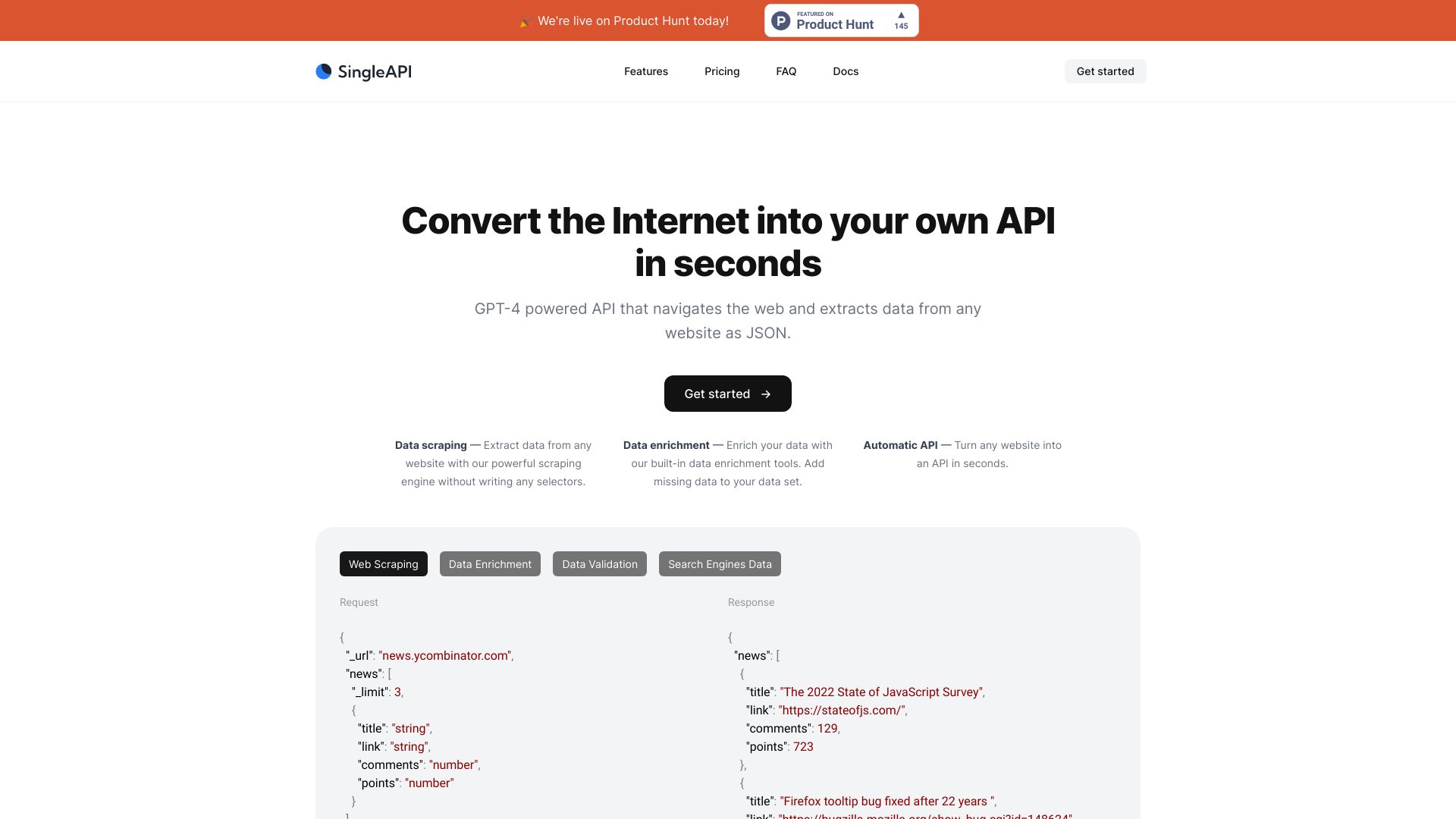
SingleAPI is a web data extraction API that presents itself as a GPT-powered way to turn websites into structured data. Its official site and documentation position the product around extracting fields from web pages through an API instead of writing a custom scraper for every target. This is useful for teams that need data from many semi-structured pages but do not want to maintain brittle parsing code.
The important buyer question is reliability. AI can make extraction more flexible, but production data pipelines still need repeatable schemas, monitoring, retries, and compliance review.
Best-fit use cases
| Use case | SingleAPI fit | Notes | |---|---:|---| | Prototype web extraction | High | Strong for quickly testing data extraction ideas. | | Semi-structured page parsing | High | Useful when pages vary but fields are predictable. | | Competitive or market research | Medium to high | Works when access rules and source quality are reviewed. | | Mission-critical regulated data | Medium | Needs stronger validation and audit controls. | | Sites that forbid scraping | Low | Respect terms, robots, and legal constraints. |
What teams should verify
Teams should test schema stability, extraction accuracy, rate limits, retries, source permissions, robots.txt, legal constraints, latency, cost per request, error handling, and how the API behaves when page layouts change. AI extraction should be treated as a parser that needs monitoring, not as a guaranteed truth source.
The best use is often a hybrid workflow: use SingleAPI to accelerate extraction, then validate outputs against rules, sampled human review, or downstream data quality checks.
Strengths
- Useful for turning web pages into structured data without writing a bespoke scraper for every site.
- Good fit for prototypes, research workflows, and semi-structured sources.
- API-first approach is easier to integrate into data products than manual scraping.
- Documentation is available for implementation planning.
Limitations
- AI extraction can be inconsistent without schema validation.
- Legal, robots.txt, and source terms must be reviewed before collection.
- Page layout changes can still break pipelines.
- Mission-critical use needs monitoring, retries, and sampled QA.
Bottom line
SingleAPI should be indexed as an AI-assisted web data extraction API. It is most useful for teams that need structured data from semi-structured pages and are willing to wrap AI extraction with validation, monitoring, and compliance checks.
Sources reviewed: SingleAPI homepage, SingleAPI documentation, SingleAPI product section.
FAQ
What is SingleAPI best for?
SingleAPI is best for extracting structured data from semi-structured web pages through an API, especially during research, prototyping, or data product development.
Does SingleAPI eliminate scraper maintenance?
It can reduce custom parser work, but teams still need monitoring, schema validation, retries, and checks for layout changes.
What should teams check before using SingleAPI?
Check extraction accuracy, schema stability, rate limits, pricing, robots.txt, site terms, legal constraints, error handling, and downstream data quality.